

Do You Like It?
Can machines be made to silently ‘learn’ our aesthetic preferences? Can we empirically decode our intuitive likes and dislikes? Can the game of numbers intrude upon the world of art? Can creativity, in turn, be mechanized?
‘Do you like it?’ is a very simple set of tiny experiments testing out the possibility of algorithms to decipher our intuitive aesthetic preferences with respect to abstract forms. The first and simplest experiment was ‘Make me a Vase’.
‘Make me a vase’ started out by testing the degree to which simple classification algorithms would predict whether or not a subject would ‘like’ a randomly generated curvilinear form (loosely resembling a vase). It then went on to test out the accuracy with which an artificial neural network could predict how much (on a scale of 10) a subject would rate the forms based on their intuitive aesthetic preferences.
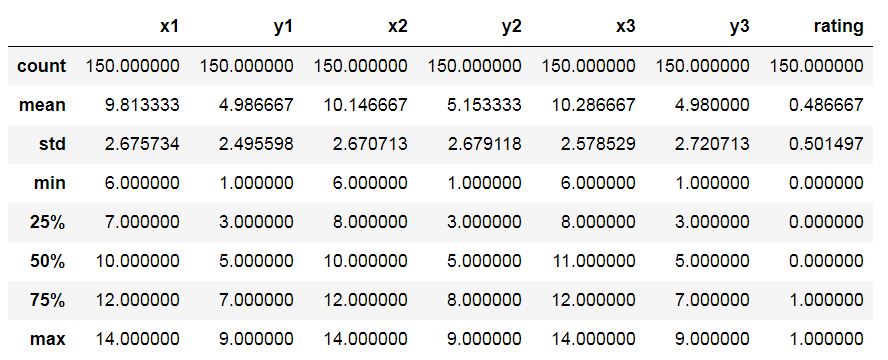
For the experiments, a set of 150 algorithmically generated forms were presented sequentially to a subject using a custom Python script, and they were asked to place each of them in one of two categories – ‘I like it’, and ‘I do not like it’. The categories for each were noted as inputs within the graphical interface (Rhino3d).

What the subject was not told (but may have subconsciously registered) was that each of the forms was in fact made up of a collection of 3 ellipses of randomly generated major and minor axis lengths (x and y). The x and y values were randomized within a certain range to give rise to each of the 150 forms.
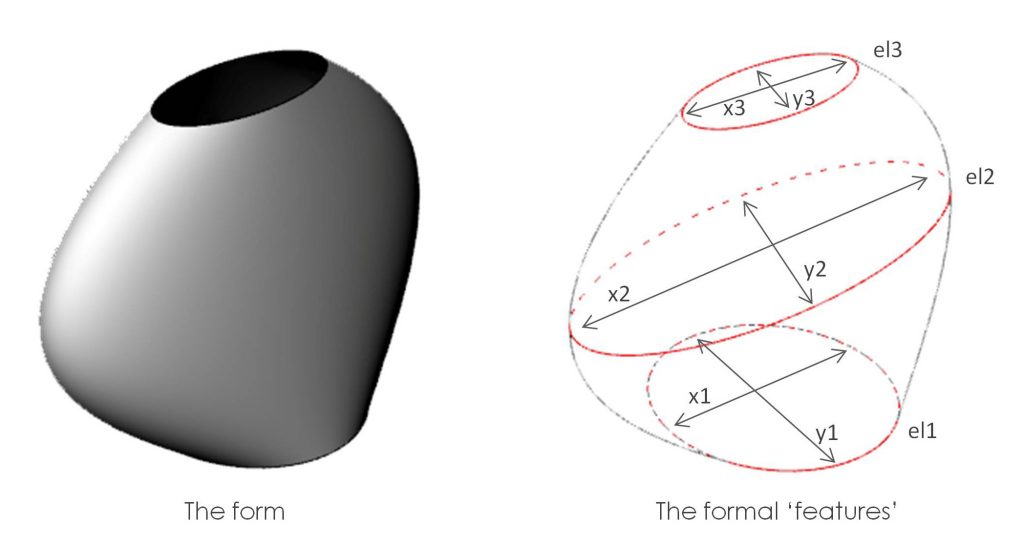
Each cycle of the subject recording his intuitive aesthetic judgement (recorded as a 0 or a 1) was accompanied by an automated recording of the six primary ‘features’ of the form, namely (x1, y1, x2, y2, x3, y3). The experiment thus gave us training data for an algorithm to try and make sense of.
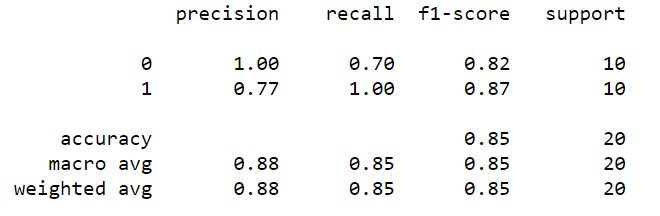
First, a simple K – Nearest Neighbour Classification model was applied on this six dimensional training data set. A small sample from this training set was used as a test set, and the K value was modulated to try and minimize the prediction error rate. The model was ready for new predictions.
The experiment was then repeated on the subject for a test sample of 20 new random forms. This new set of values for the ‘features’ of this test set was fed into the algorithm for classification based on the training data.
The algorithm was able to correctly predict whether or not the subject found the form aesthetically pleasing 17 out 20 times (an accuracy of 0.85). Predictions were made again on a new test set, with an accuracy of 0.70. The entire experiment was repeated on 3 subjects, on multiple test sets, with accuracy varying between 0.7 and 0.9 and an average accuracy of 0.78.
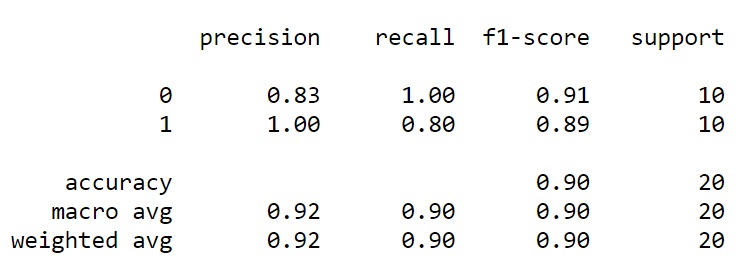
The training datasets for each subject were then also fed into a Random Forest Classifier to try and improve classification accuracy. In almost all cases, the Random Forest Model performed better than the KNN algorithm, with accuracy ranging between 0.85 and 0.90, and with an average accuracy of 0.867.
Finally, the entire experiment was repeated as a regression exercise. This time, the subjects were asked to rate the ‘vases’ on a scale of 1 to 10, depending on their personal intuitive aesthetic preferences. The data sets were fed into an artificial neural network with 6 dense layers and rectified linear unit activation functions. The models were trained on the data through 400 epochs, and were ready for new predictions.
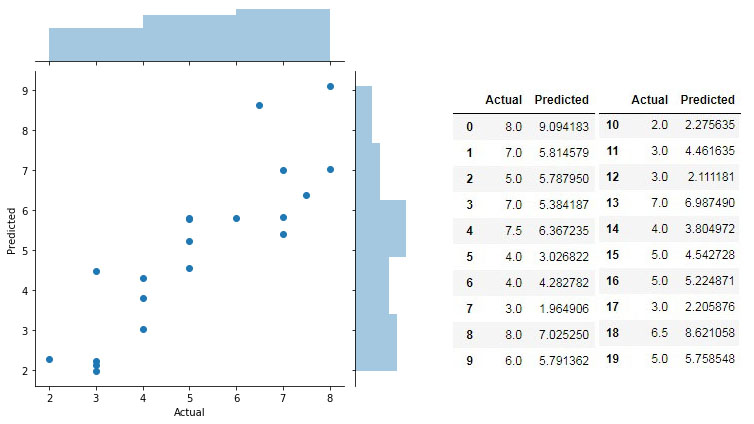
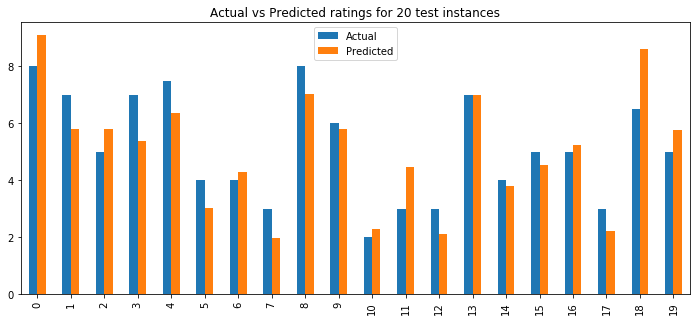
The subjects were then asked to rate a test sample of 20 new forms (similar to the earlier classification exercise). The features of the test set was fed into the ANN for regression. The model was able to predict the ratings with a root mean squared error of 0.903 (around 10% error on a 1 – 10 scale) and an explained variance score of 0.72. The figures below show scatter and bar plots of Predicted vs Actual ratings for 20 test vases for one subject.
————
As mentioned earlier, these experiments were very simple tryouts of the applicability of statistical learning models within the realm of aesthetic judgement and affective response to abstract forms. More advanced and appropriate models will be suited to handle a greater degree of complexity with regards to features of everyday form and space. Affective computing has already been making steady progress in allied domains over the years. The way that each of us make ‘intuitive’ decisions with respect to the aesthetic realm have already begun to be broken down into 0s and 1s. Does the future of art lie in numbers?
Do watch this space. I’ll be adding results from more such tiny experiments soon.